学习数据分析,做大数据紧缺人才
机器学习:开发人员和业务分析师须知
要成功应用机器学习,光有数据科学是远远不够的。
由于新技术和新方法的出现,机器学习正在经历一场革命。机器学习是一个使用程序开发功能的过程(例如通过分析数据而不是为确切的步骤编程)把垃圾邮件和可取的邮件区分开来,从而使用户无需做出关于算法的工作方式的每一个决定。机器学习是一个强大的工具,不仅因为每天有逾百万人专注于繁琐的编程步骤,还因为它有时会找到比人工操作更好的解决方案。
机器学习在大多数行业中都得到了应用,在这些行业里,它为现有流程提供了改进的绝佳机会。但是,很多企业都在努力跟上创新。诚然,找到熟练的数据科学家是困难的,但技能短缺并非故事的全部,特别是对于那些已经做出投资但没有意识到自身潜力的组织来说。最严重的障碍与这两者间的差距有关——有能力实施各种方法的数据科学家和能够推动必要组织变革的商业领袖。
让机器学习在组织中取得成功,这需要一个涉及专家和非专业人士的整体战略。这需要关注组织,分析业务案例,以确定机器学习可以在什么地方增加价值并管理新方法的风险。例如,数据科学团队可能有兴趣使用机器学习,但由于时间限制,风险规避或熟悉度不够而选择不这样做。在这些情况下,更好的方法可能是创建一个单独的项目,把重点放在未来项目的奠基。一旦该组织有机器学习的实例,未来实施的门槛就会显著降低。
这意味着组织中的非专业人员需要分担机器学习的愿景,使其获得成功,而这始于一种共识。学习蕴藏在数据科学背后的分析和数学需要花费数年时间,但对于业务领导者、分析师和开发人员来说,至少要了解应用该技术的地方,方式以及基本概念。
使用机器学习需要一种别样的解决问题的方法:让机器学习算法解决问题。这是熟悉如何通过功能性步骤进行思考的人的思维转变。需要相信机器学习计划会产生结果并且需要耐心。
机器学习和深度学习
为什么机器学习如此强大?机器学习的工作有很多不同的流程(有算法推动),我将在下面详细讨论,但是处于领先地位的流程使用神经网络,其结构与生物脑的结构相似。神经网络具有多层连通性,当它有很多复杂层次时,我们就把它称为深层神经网络。
深度神经网络直到最近才取得了有限的成功,当时科学家利用了通常用于显示3D图形的GPU,他们意识到GPU具有大量的并行计算能力,并用它们来训练神经网络。结果非常有效,以至于现任的数据科学家都措手不及。训练深度神经网络的过程称为深度学习。
深度学习在2012年已经成熟,当时加拿大团队首次将GPU训练的神经网络算法引入重要的图像识别竞赛,并大幅度领先于竞争对手。第二年,60%的参赛作品使用深度学习,次年(2014年)几乎每一个参赛作品都使用它。
从那以后,我们看到硅谷出现了一些非凡的成功案例,让谷歌、亚马逊、贝宝和微软等公司能够为客户提供服务并了解他们的市场。例如,谷歌使用DeepMind系统将数据中心冷却所需的能源减少了40%。贝宝则用深度学习来检测欺诈和洗钱。
除了这个重心之外,还有其它一些成功案例。例如,西奈山伊坎医学院(Icahn School of Medicine at Mount Sinai)利用英伟达的GPU来构建一个名为Deep Patient的工具,该工具可以分析患者的病史,以预测发病前一年内将近80种疾病。日本保险公司AXA采用深度学习模式,将汽车事故预测率从40%提高到78%。
有监督学习和无监督学习
在基本的层面上,有两种类型的机器学习:有监督学习和无监督学习。有时候这些类型会进一步得到分拆(例如半监督和强化学习),但本文将重点介绍基础知识。
在监督学习的情况下,你通过将已知的输入和输出传递给监督学习来训练模型进行预测。一旦模型看到了足够的例子,它就可以从类似的输入中预测到可能的输出。
例如,如果你想要一个可以预测某人患病的概率的模型,那么你需要随机人群的历史记录,其中有指示风险因素以及是否患有病症的记录。预测的结果再好也好不过用于训练的数据的质量。数据科学家通常会扣留培训中的一些数据,并用它来测试预测的准确性。
在无监督学习的情况下,你需要一种算法来查找数据中的模式,而你无法提供示例。在聚类的情况下,算法将数据分类为组。例如,如果你正在进行市场营销活动,则群集算法可以找到需要不同营销信息的客户群,并发现你可能不知道的特有群体。
在关联的情况下,你希望算法找到描述数据的规则。例如,算法可能已经发现,在周一购买了啤酒的人也购买了尿布。知道了这些信息,你可以在星期一提醒啤酒顾客购买尿布,并尝试提升特定品牌的销售。
正如我上面提到的,机器学习的应用除了要理解数学和算法外,还要有一些远见。他们需要理解业务的人员,理解算法的人员和能够关注组织的领导者共同努力。
机器学习的流程
机器学习模型的实施除了简单地执行算法之外还涉及很多步骤。为了流程在组织的规模上工作,业务分析师和开发人员应该参与一些步骤。工作流通常被称为生命周期,它可以通过以下五个步骤进行总结。请注意,某些步骤不适用于无监督学习。
1.数据收集:要让深度学习发挥良好的作用,你需要大量准确一致的数据。有时数据要从不同的来源收集并得到关联。尽管这是第一步,但它往往是最困难的。
2.数据准备:在这一步中,分析人员确定数据的哪些部分成为输入和输出。例如,如果你试图确定客户取消服务的可能性,那么你可以将单独的数据集合在一起,挑选模型所需的相关指标,并消除这些指标中的歧义。
3.培训:这一步由专家接管。他们选择最好的算法并反复对它进行微调,同时将其预测值与实际值进行比较,以查看它的工作效果。依据学习类型的不同,你可以期望自己会知道其准确性水平。在深度学习的情况下,这一步可能是计算密集型的,它需要占用数小时的GPU时间。
4.推论:如果目标是要让模型进行预测(例如监督学习),那么你可以部署模型,以便它对查询做出快速响应。除了输出是预测之外,你给它与数据准备期间选择的输入相同。
5.反馈:这是一个可选步骤,来自推理的信息用于更新模型,以便提高其准确性。
以下例子显示了监督学习模型的工作流程的部分内容。Kinetica上的大数据存储是由GPU加速的数据库,其中所包含的训练数据可通过利用数据库的机器学习特性的模型作为学习步骤的一部分进行访问。然后将模型部署到生产系统,该系统里的应用程序要求低延迟的回应。来自应用程序的数据被添加到训练数据集中,以改进模型。
使用正确的分析平台也很重要,因为一些机器学习工作流可能会在业务用户和数据科学团队之间造成瓶颈。例如,像Spark和Hadoop这样的平台在开始工作之前可能需要将大量数据移动到GPU处理节点,这可能需要几分钟或几小时的时间,同时限制了业务用户的可访问性。像Kinetica这样的高性能GPU驱动的数据库可以通过取消数据移动,把处理能力直接带给数据,以此来加速机器学习的进度。在这种情况下,几秒钟内就能返回结果,这些结果会启用交互式进程。
机器学习算法
在GPU对超深度神经网络的训练进行提升之前,这些实施方法由各种算法主导,其中一些算法比计算机的存在还早。由于这些算法的简单性和速度,它们在很多用例中仍然占有一席之地。很多入门数据科学课程都是从连续变量的预测线性回归和预测类别的逻辑回归开始讲起的。K-means聚类也是无监督学习的常用算法。
深度神经网络是深度学习的后盾,它与大多数传统的机器学习算法有很多相同的应用,但它可以扩展到更复杂的用例。推理相对较快,但培训是计算密集型的,它通常要占用好几个小时的GPU时间。
下图是图像识别的深度学习模型的图形表征。在这个例子中,输入是一个图像,节点是神经元,它们逐渐挑选出更复杂的特征,直到输出一个指示结果的代码为止。
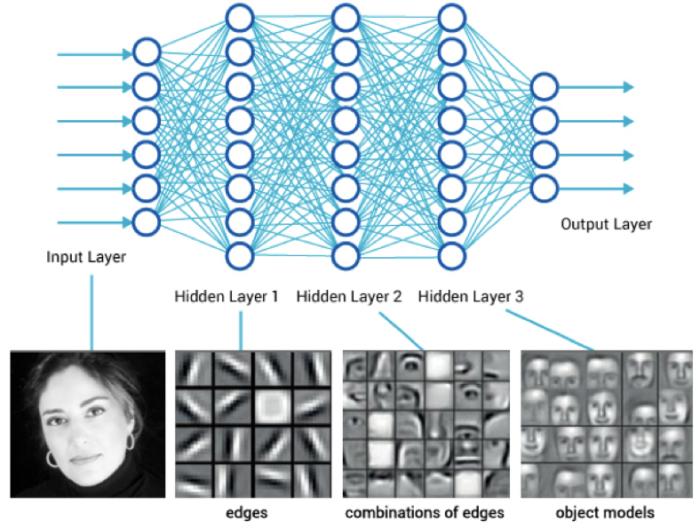
人们把图像识别的例子称为卷积神经网络(CNN),因为每个神经元都包含图像蒙版,并使用名为卷积的技术将蒙版应用于图像数据。还有其它类型的深度神经网络,例如递归神经网络(RNN),它可以处理时间序列数据,以进行财务预测和通用的多层网络,这些网络可以使用简单的变量。
我们需要考虑的一个重要问题是,深度神经网络与很多传统的机器学习算法不同,它很难进行逆向工程,或不可能进行逆向工程。更重要的是,你并不总能确定推理是如何进行的。这是因为算法可能会在成千上万个神经元中填充权重,并找到人类无法理解的解决方案。信用评分是一个例子,如果你想了解分数是如何确定的,就不应该在这个例子中使用深度神经网络。
机器学习框架
从头开始编写机器学习模型可能很乏味。为了简化实施方法,可以使用框架来规避复杂性并减少数据科学家和开发人员的障碍。以下是一些比较流行的机器学习框架。
例如,谷歌提供了一个名为TensorFlow的流行框架,它以支持图像和语音识别的能力而闻名,并在TensorBoard中提供了一系列模型可视化工具。
TensorFlow的设计目的是使并行和多GPU上的深度神经网络更容易训练,但它也支持传统的算法。它可以与大数据平台(如Hadoop和Spark)一起使用,以实现大规模并行工作负载。在数据移动可能成为瓶颈的情况下,Kinetica平台使用本地的TensorFlow集成,把GPU加速的工作负载直接带给大数据集。
TensorFlow在模型(称为估计器)和算法(称为优化器)之间进行抽象,它可以让用户在训练模型时从多种算法中进行选择。例如,专家可以以简单线性回归作为算法来编写监督学习模型,然后将其与深度神经网络算法进行比较。
历史重演
机器学习的兴起与互联网的兴起有着惊人的相似之处。这两项研究数十年来都是由大学研究人员展开的,并得到了有限的商业使用。互联网基于1969年启动的一个网络,它在90年代已经成熟,这些网络扰乱了有这种在位企业的行业——反应迟钝,直到业务被边缘化。现在和互联网一同崛起的公司都在引领机器学习的发展,而在位的公司则试图了解其重要性,并从数据科学投资中提取价值。
任何让组织洞察业务的软件项目都需要业务用户和具备将业务需求转换为代码的技能的人员之间的密切参与。大多数投资了软件的组织都熟悉这种模式。一个关键的区别是,虽然机器学习需要对问题进行定义,但它的目的是寻找解决方案。
机器学习的广泛采用要求业务分析师和软件开发人员在与数据科学团队进行交流时至少了解黑匣子级别(black-box level)的知识。还要求业务领导者了解如何通过机器学习解决以前通过认真定义的规则解决的问题,从而实现价值。成功使用机器学习并不需要大多数人来了解机器学习的细节。但是他们需要足够的了解,这样才能向数据科学专家提出正确的问题。
作者简介:
Chad Juliano是Kinetica的高级解决方案架构师。此前,Chad是甲骨文的高级首席顾问。在加入甲骨文之前,他曾在Quorum Business Solutions担任软件工程师。Chad还在门户软件方面有过经验。Chad在达拉斯的南卫理公会大学获得电气工程和数学双学位。
来源:企业网D1Net

来源:企业网D1Net
未来的制造业要的不是石油,它最大的能源是数据.